A Simple Launch-and-Go-Away Multiprocessing Architecture
In many situations we may want to launch a background task to do something that is uncontrollable, dangerous and may block the main program for a long time or even forever. For example, a FTP uploading or downloading, or a complicated computation that relies on modules of different qualities. For those operations, you don't want to run them in your main process, you want to isolate them as much as you can.
Here I'm only addressing this kind of situation: you launch the task, set a timeout for it, and you are good to go. You don't care if it will succeed or not and you don't retry it on failure. It should be killed automatically if it runs out of time (Why? Because otherwise it will become a zombie and stick there forever and never release any resource).
This design is very useful in situations where you don't care about occasional data loss.
Thread or Process?
I would use multiprocessing. Not only because a thread can neither be killed, nor can it terminate itself in Python, but also because of the extra overhead on multicore systems, which is very common nowadays, introduced by the infamous GIL.
Regarding the GIL issue, here is a perfect insight: Inside the Python GIL. It illustrates the gigantic overheads using threads. Here is the picture that visualizes this problem very well.
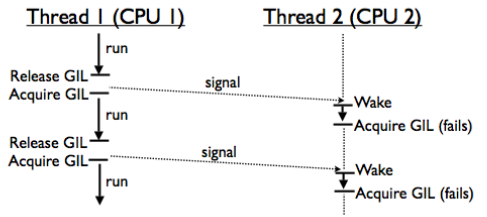
Put it simply, on a multicore system, a thread will be scheduled to run immediately (on another core) once the OS is signaled that a previously running thread has released its GIL. But when it can start to run, the GIL is already gone. It's because with multiple cores, threads in ready state get scheduled to run on different cores at the same time so they compete for the GIL.
In the above figure, Thread 2 on CPU 2 gets signaled every time Thread 1 releases GIL, but it cannot start to run before Thread 1 acquires the GIL again due to the signal passing and scheduling overheads.
Be very careful with Python multithreading, especially in multicore systems.
Architecture
Remember we just want to launch a separate process to run, we don't want our main process to wait for it to finish or to continuously monitor its state. Once the process is forked, our main program shouldn't care about it anymore otherwise it will be slowed down.
How to achieve this? It turns out we can just wrap the worker process in another process which should be responsible for the worker's lifecycle. We call it the manager process here. The design looks like this:
def worker(queue):
# Read from the queue
msg = queue.get()
'''
process the work here
'''
queue.task_done()
def manager(task_queue):
'''lifecycle manager of the worker process'''
worker_p = Process(target=worker, args=(task_queue, ))
worker_p.start()
worker_p.join(TIMEOUT)
if worker_p.is_alive():
logger.error('worker process timed out, killing ...')
worker_p.terminate()
if __name__ == '__main__':
task_queue = Queue()
for item in database.feed():
manager_p = Process(target=manager, args=(task_queue,))
manager_p.start()
task_queue.put(item)
task_queue.join()The main program can focus on fetching data from database and dispatch it to workers. We can do all the ugly and dangerous stuff in the worker processes without worrying the main process getting contaminated. The lifecycle manager takes care of all the clean-ups.
An optional third-party module
There's a neat Python module called Pebble that can do the same thing for you. The design is similar, it also uses a lifecycle manager to manage the actual worker process. The difference is that the manager is implemented as a daemon thread instead of a process.
comments powered by Disqus social sharing buttons